We’re currently hearing a lot about how generative AI, particularly large language models like ChatGPT, could replace white-collar knowledge workers. And venture capitalists are, at least in a large part of their job, knowledge workers. So which parts of a VC’s job could AI take over?

To start with the conclusion: The current generation of LLMs is not nearly capable enough to replace (even very junior) VCs. But there is little doubt that AI tools have reached a level of maturity that can meaningfully augment VCs and similar professions in their daily jobs, particularly with first drafts of tedious tasks.
To explore what is possible right now (in May of 2023), I conducted three experiments to figure out how to augment typical VC tasks:
- Writing investment memos
- Conducting market analysis
- Making intros
Investment Memo
When VCs like a company and are seriously considering an investment, they write an investment memo. That’s a multi-page document that outlines the startup’s strengths and weaknesses and makes a recommendation to the investment committee. Writing such a memo is an important analytical task, but also tedious because assembling all the relevant data points is quite a lot of manual work.
The little Python program I wrote for this experiment is capable of taking PDF pitch deck for a startup as-is to automatically generate a 7–8 page investment memo with all necessary details — except pictures and tables at this point. An earlier version based on GPT-3 consistently made a lot of mistakes, but the GPT-4 version is remarkably reliable. It occasionally is confused by really complicated slides, but it gets most details right, even from complex numerical tables. The result is certainly not perfect and complete, but more than good enough as a first draft.

As an example, here’s some output based on the original seed pitch deck from our b2venture portfolio company Edurino. The model came to very positive conclusions. Spoiler: We at b2venture ended up investing, so the model is right. The following pictures are unedited outputs created by the model, redacted for confidentiality.


The next picture is the prompt for the model that describes in detail what an investment memo is and what each section does. To get useful results out of GPT-4, it is essential to carefully craft these prompts. This particular one is probably version 20 or so.
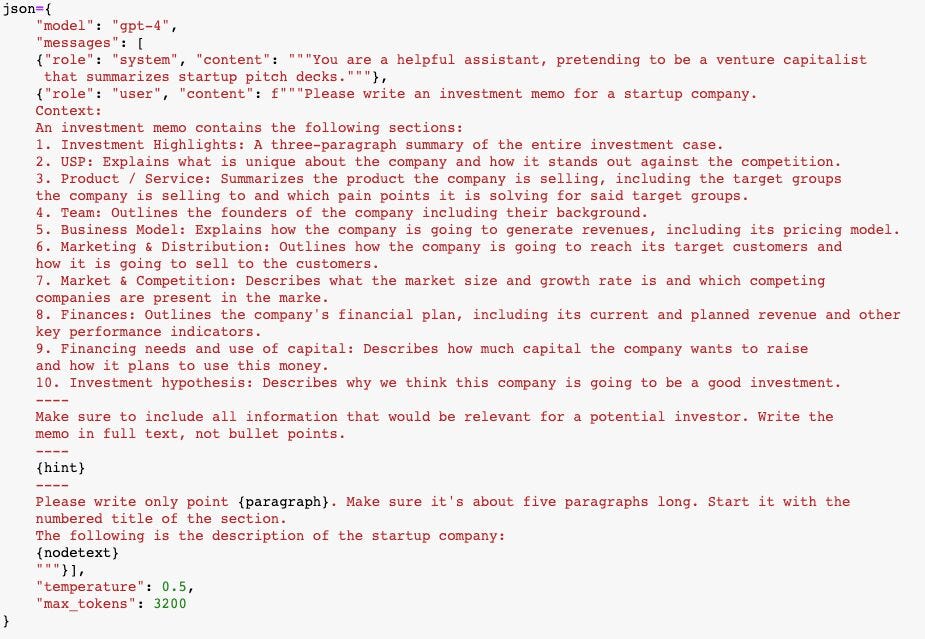
Since GPT-4 is still quite slow and expensive, this takes about 5 minutes and costs a whopping $1.50. Not too terrible for something that would take several hours to do manually.
Market Analysis
Analyzing a market sector and the various players in it is one of the most important, but also most time-consuming tasks in venture capital. Most markets today are very dynamic and noisy, so you often have to look at dozens of companies (both startups and incumbents) to understand what is going on. Just finding all these companies can take days.
So how could AI help? Inspired by some recent developments in autonomous AI (such as the AutoGPT framework) I put together a prototype that is able to come up with first draft of a market analysis just based on a company name — typically the startup you’re considering to invest in — and a couple of high-level keywords describing the sector. The prototype then conducts a market analysis independently.
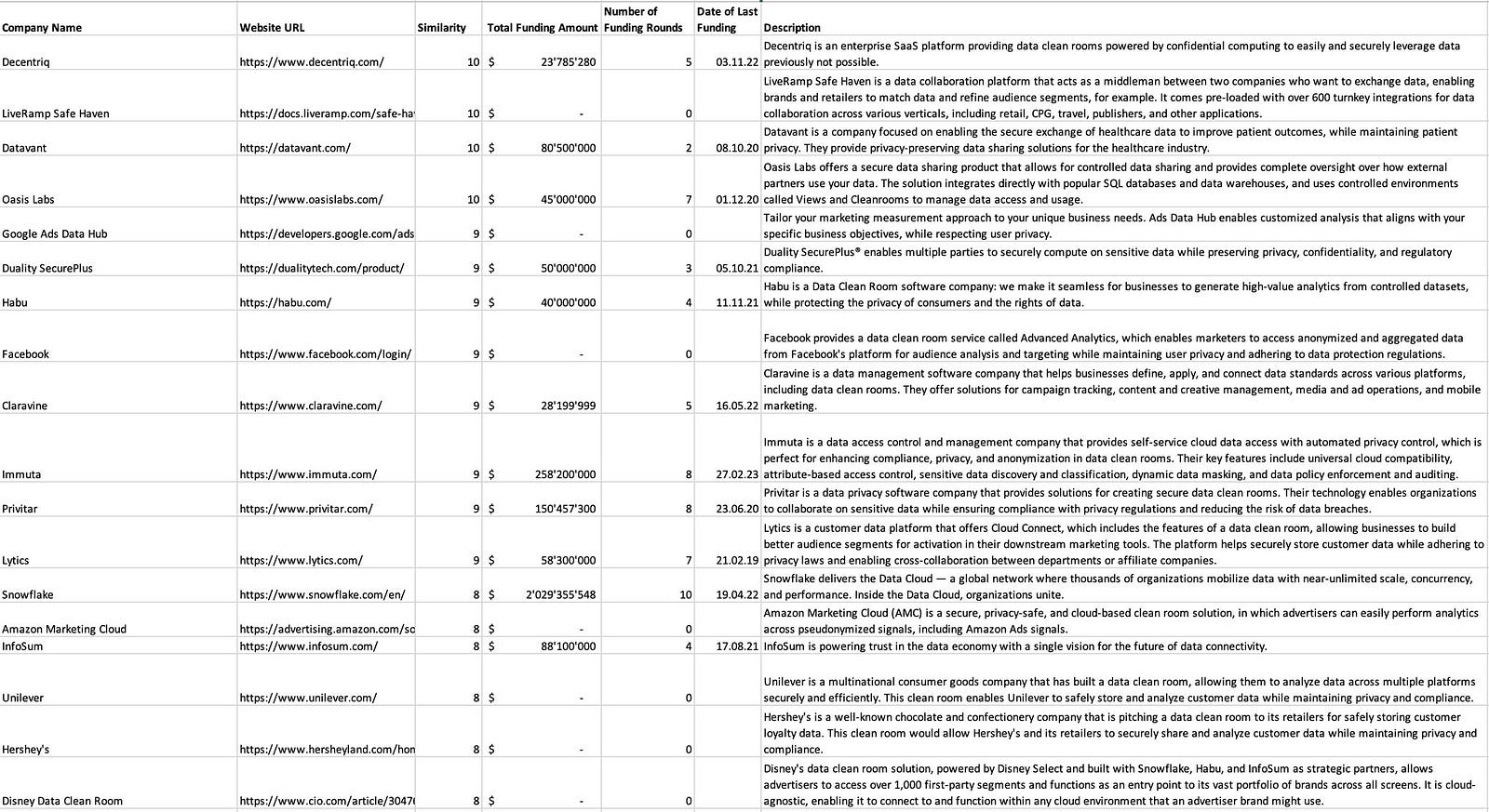
The result is quite remarkable. I’m using our existing b2venture portfolio company Decentriq as an example here because its market is very dynamic, not easy to understand for outsiders and consists of a mix of startups and large incumbents.
The GPT-4-based prototype can fully automatically identify several dozen relevant companies, both direct and indirect competitors. It can write a short market summary as an introduction. And most surprisingly, it can come up with relevant differentiation factors and rank companies accordingly in order to create a typical 2×2 competitive matrix. All of this takes about half an hour and costs something like $2–3 in API fees.

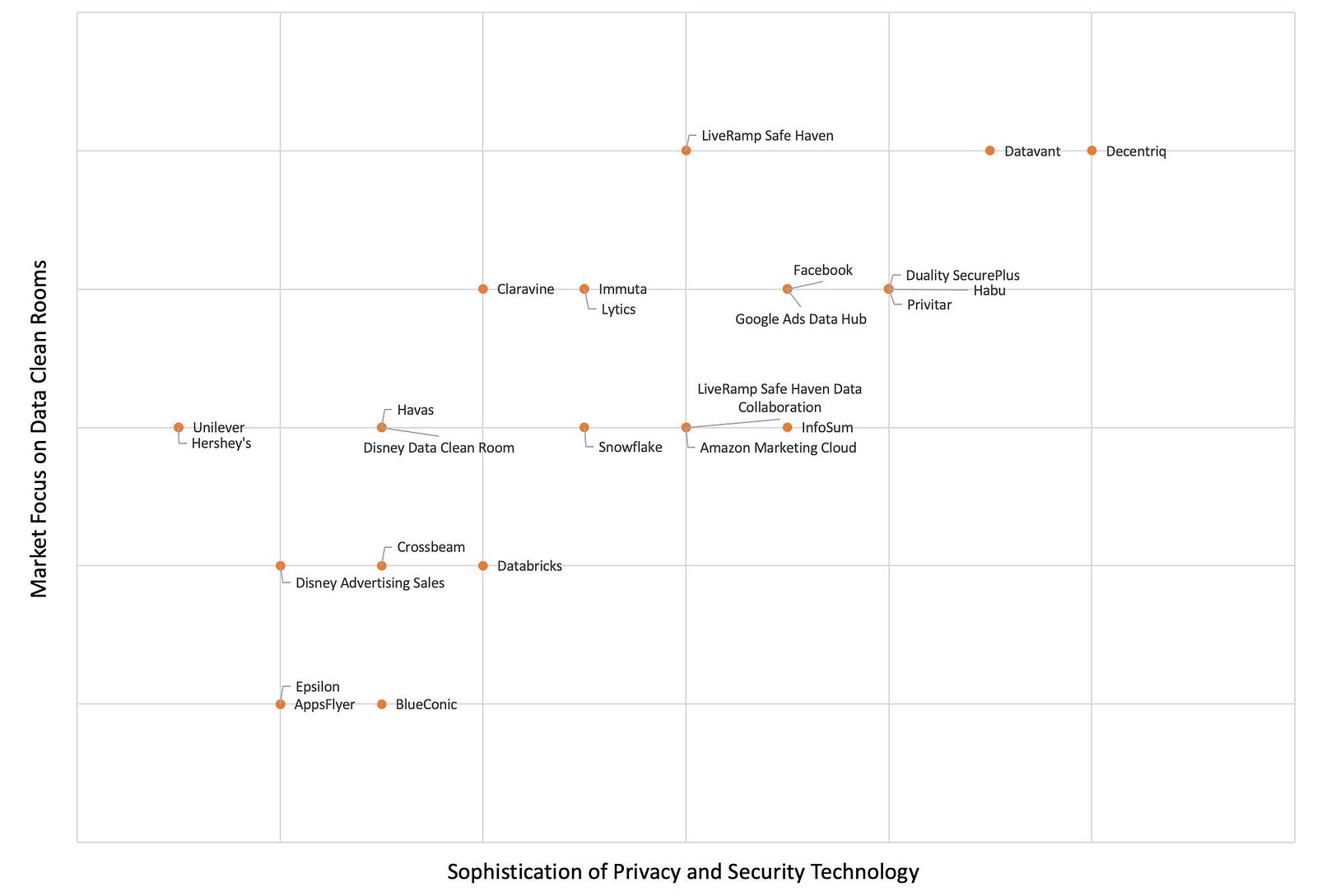
Of course this is only a starting point for a real market analysis. Experts will have a lot of comments and different viewpoints on these results.
The two main bottlenecks: The AI can only analyze public information, which may or may not be accurate. And in complex markets, it’s often not easy to understand subtle nuances between companies and sub-sectors (granted, that’s a challenge for human analysts too).
So how does this work? The prototype uses GPT-4 as the analysis backend, but also quite a lot of Python trickery to get and process raw data.
- The system conducts several web searches to identify useful web pages describing the industry. GPT-4 predicts the relevance of each page so that the further process can focus on the most useful content.
- GPT-4 then analyzes these pages and identifies relevant companies from the content, along with a description and relevance ranking for each company.
- The system finds the funding status for each company from a data warehouse containing Crunchbase data (from the paid Crunchbase API)
- The system then asks GPT-4 to write a market summary and come up with the raw data for the 2×2 matrix.
Again, the output has — like so many AI-generated results — mostly the character of a first draft. But the saved effort is considerable, and I have found that every time I even learn something new about markets that I’m very familiar with.
It’s also great to go into initial calls with startups with already a first solid understanding of what current market conditions are like — created by the market research assistant in a few minutes in the background. The most important aspects that VCs want to understand early on is how a given startup differentiates itself. Any additional insight into its market is therefore very useful for this discussion.
Network Mining
VCs make a lot of introductions. Frequently, portfolio companies want to be introduced to potential customers, advisors or potential investors for future funding rounds. Making these intros is one of the best ways in which VCs can help.
This sounds easy enough, but in reality it’s not trivial. If you’re like me, you have thousands of contacts on LinkedIn and elsewhere, ranging from close friends to people I’ve talked to for two minutes at a conference in 2005. And of course people keep changing jobs, so figuring out who might be in a relevant position right now is not easy.
Most professionals now have a reasonably current LinkedIn profile, so that’s a starting point. But unfortunately, LinkedIn’s search features are pretty dismal, which makes finding the right person still hard.
To make my LinkedIn contacts more searchable, I used generative AI and semantic search. I did the following:
- Scrape my LinkedIn contacts with one of the several readily available scrapers. This is still a tedious process (shame on LinkedIn for not having an API), but it does the job.
- Expand the most important profiles with a full, GPT-4 generated summary of the entire profile. This is relatively costly and slow, so I only did this for the most important profiles. For the rest I just used the job title, company and headline.
- Create embeddings (vector representations of the profile text) using OpenAI’s embeddings API.
- Write the profile embeddings to a vector database. I tried Pinecone and FAISS, which provided comparable results. This makes the profiles immediately searchable in a semantic way, i.e. there doesn’t have to be a full keyword match, but the database can identify concepts that are similar to what you’re asking for.
- I then wrote (or rather asked GPT-4 to write, which it did in seconds) a small web app that lets me search the database.
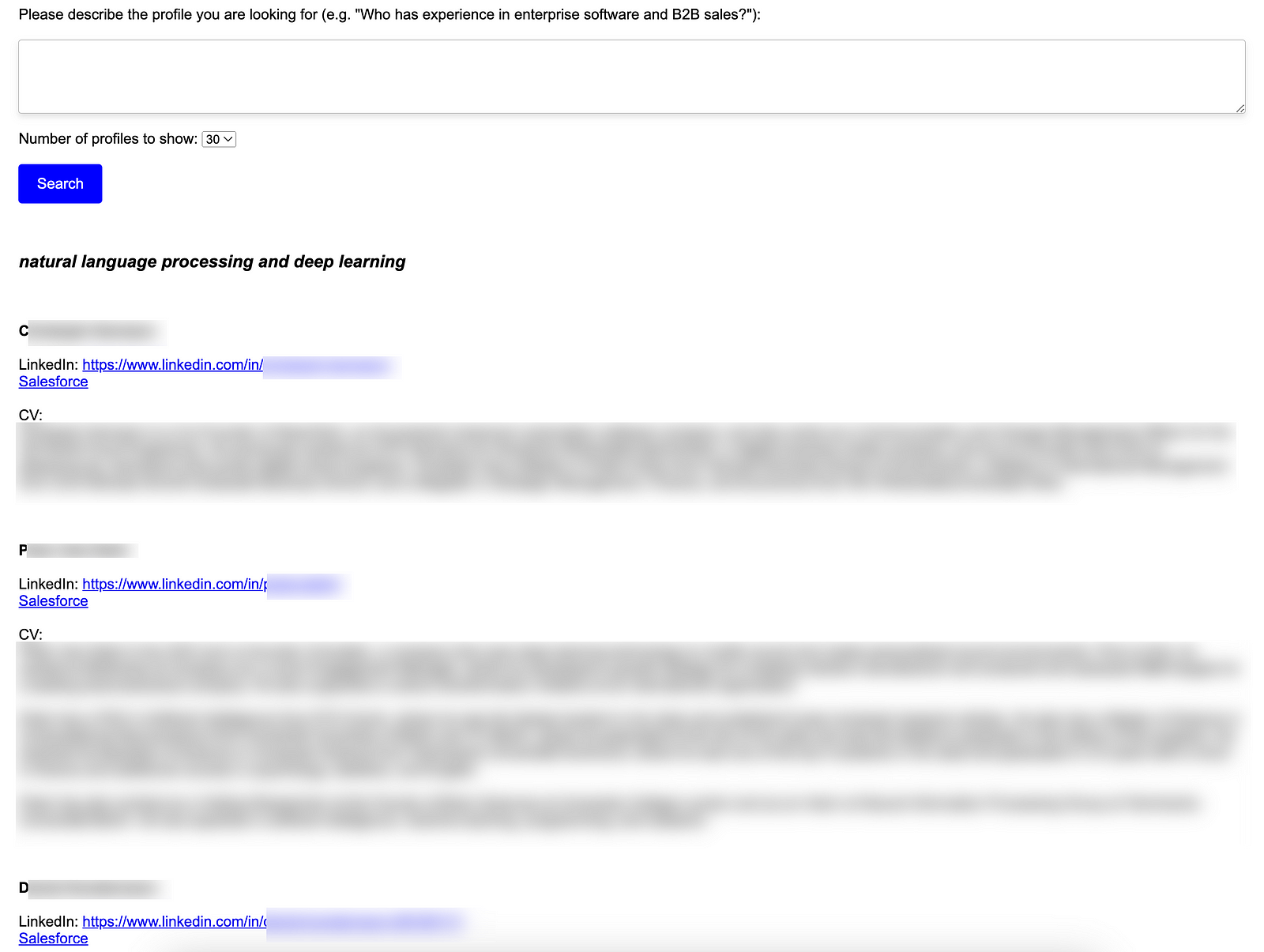
The results are often quite eye-opening and make mining the network very convenient. For example, you can start just searching for a company name, and the system will provide contacts who work at that company, but also others who work in similar companies in the same industry or even adjacent industries.
This is not perfect by far. Quite often, it’s not clear why the search engine is providing a result that doesn’t seem to have much to do with the original query. But filtering out this noise is much easier than finding the right people in the first place, so it’s still a huge time saver. And on the positive side, you keep seeing profiles of people that you might never have thought of, but could actually be relevant in a more indirect and creative way.
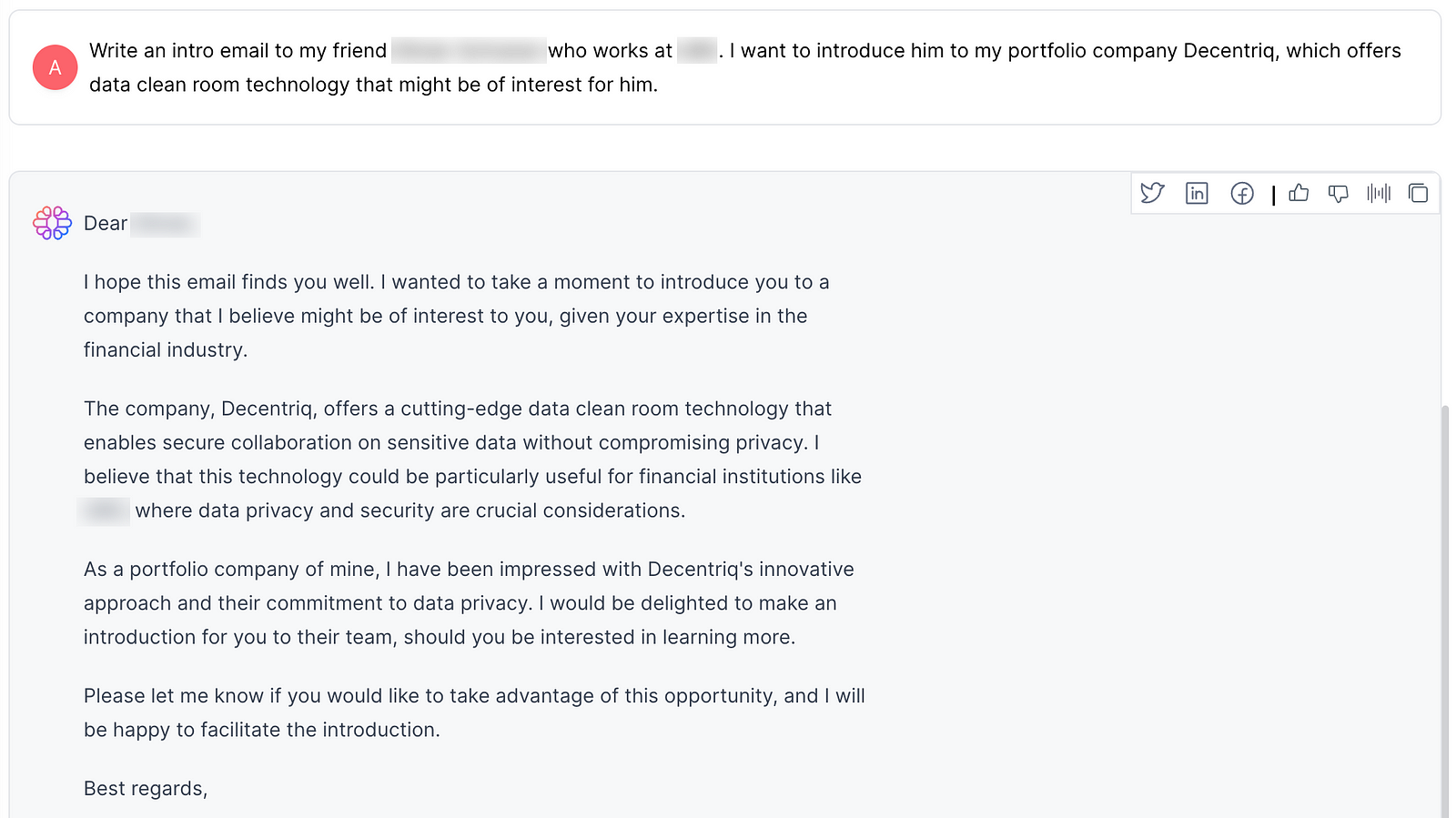
Of course generative AI can then also help you write the intro texts to the people you want to contact. I use our portfolio company TextCortex’s tools for this. Their next generation product will be able to mimick my style even better. But it’s amazing how TextCortex’s Zeno assistant already gets facts right that I didn’t even mention.
A few things I’ve learned
Most of us by now have played with ChatGPT and similar tools, and you have almost certainly experienced these magical moments when the machine did something that you didn’t expect.
But anybody who has been in tech for long enough knows: there’s a long way from the cool demo to something that people will use on a regular basis and that will truly move the needle in a business.
My experiments showed that GPT-4 (as the currently most advanced language model) is really good at a few things:
- Summarizing text in a very smart and mostly precise way
- Extracting information from unstructured text
- Coming up with first drafts of deliverables
- Finding patterns
But there are a lot of problems for the use cases described above:
- The well-known problem of hallucinations — the model making up something out of thin air — is a problem on several levels. Even if you tell GPT-4 to just stick to the facts you’re providing, it will occasionally still invent something else. And even very clear instructions — like “don’t number the companies that you are extracting from this text” — are ignored about 5% of the time. It’s not clear how this can be controlled perfectly.
- Current models have a fairly tight “token limit” that restricts the size of inputs and outputs. For example, GPT-4 currently has an 8k token limit, which translates to about 4–5k words for both input and output. That’s not too bad, but means that you can’t feed it large documents. In practice, this means that you often have to split up inputs into smaller chunks, which creates its own problems from losing context.
- Garbage in, garbage out: That’s true for language models as well. When you use external data sources like web searches, it’s crucial to control carefully what you are providing as the input. There is a lot of human-led tweaking necessary to get the right results.
- The recent hype around “agent-based” frameworks like AutoGPT might suggest that AI models can already act independently. In my experience, that’s far from the truth. A complex task like a market analysis still has to be carefully scripted to produce a usable result. However, there is certainly a path to more autonomous systems.


